
At Jimdo we are committed to providing our users with the easiest website builder on the web. Behind the scenes, of course, that includes security related topics - most notably HTTPS. But web security is actually not an easy topic and even though it could be considered natural these days (and things are definitely improving), still way too many websites are not secure.
Recently, we tasked ourselves with doing our part to contribute to the HTTPS everywhere movement and built a solution to support HTTPS for every one of our users’ custom domains. The solution had to be as easy as possible by definition for our users, and the outcome ultimately requires no human interaction.
Every Jimdo user today has HTTPS support by default on his website and this is the story of how we got there.
the journey begins
Jimdo users own millions of custom domains, including awesome domains like the one of our not-scared-of-heights co-founder Fridel. It can be considered an easy task to introduce HTTPS to your company website, but what if you have millions of website you have to serve?
During our evaluation we revealed the following questions:
- How and where do we order and renew millions of certificates, automated, and for a reasonable price?
- How do we serve millions of certificates, as a typical web infrastructure is usually made for serving just a few?
- How do we upgrade our existing customer websites from HTTP to HTTPS? We really don’t want to put this burden on our users!
Ordering process
Requesting the generation of certificates could be considered a huge pain point. In the past it involved a manual process with way too much human interaction for a million certificates. But luckily time doesn’t stand still! During late 2015 the ACME protocol emerged and shortly after Let's Encrypt, “A free, automated, and open certificate authority,” was born.
In order to generate a certificate you have to solve an ACME challenge, which in short means you have to request a challenge at the certificate authority, which will respond to you with a token. An HTTP endpoint is called at the given domain, which is expected to respond with the specific token. Afterward, the domain is “authorized,” and you can request a certificate for it.
As a single certificate can contain more than one domain, we decided to bundle certificates per website, which had the great side-effect of cutting the amount of certificates we had to host and serve by roughly 50%.
The so called “certificate service” we built basically had two major components. The first one is an internal API layer that takes order requests and stores them inside a message queue and also serves existing certificates from the data store. The second component is a worker tier which handles the actual ordering process and stores newly issued certificates in our data store.

One additional task the workers solve is the renewal of certificates. Periodically we check our dataset for expiring certificates and push them to a message queue, so our worker tier can consume them. We do this about 4 weeks in advance to be safe even though the actual certificate is valid for about 90 days.
For our data store we used DynamoDB, which introduced a very handy feature recently, a TTL for records. This means we can set a column for the TTL to the certificate expiry date and get an automatic cleanup of orphaned certificates – very cool!
Serving certificates
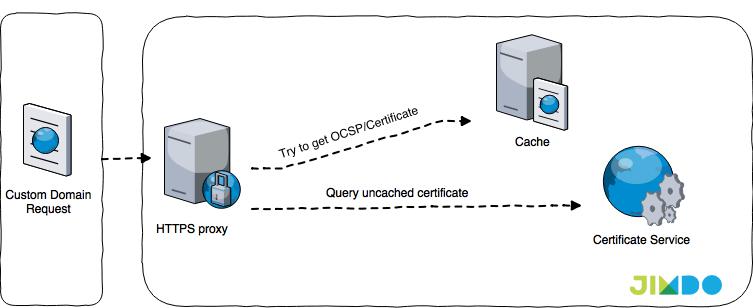
Before introducing HTTPS to Jimdo we had a combination of AWS Elastic Load Balancing and nginx for serving our users’ traffic. With HTTPS we introduced another layer in-between for terminating SSL and serving certificates as fast and reliably as possible. One part of this caching layer is a proxy node, which takes care of the TLS handshake, including serving the certificates and OCSP responses. These proxy nodes are built on nginx and OpenResty – heavily inspired by lua-resty-auto-ssl.
The second is a caching tier (redis), which takes the load off our certificate API and reduces our latency for serving our users’ websites. Unfortunately, utilizing the local nginx cache of the proxy node was not enough for us. In the Jimdo context we have requests for many different domains spread over hundreds of proxy nodes. Chances are high that a request hits a proxy node which doesn’t have the certificate in its local cache yet, and before it gets another request for this particular domain it might already be evicted from the cache. Increasing the nginx cache storage was not sufficient for us, which is why we went with a central caching solution. As a nice side effect we can now keep cache times in the proxy nodes low while doing cache eviction (e.g. we have a new certificate for a domain) via the central caching tier.
Now that we can order certificates and serve at scale it gets a little messy. For example, there is the wonderful mixed content problem – meaning you visit a website via HTTPS but it has resources (e.g. images) linked via HTTP. The browser will mark the website as “unsecured” and won’t load all resources linked via HTTP - not cool!
As we didn’t want to put the burden of fixing all these links on our users, we utilized the HTTPS Everywhere ruleset. We built a new small component which will take requests for unsecured URLs and respond with upgraded HTTPS URLs where possible via the given ruleset. That means whenever we serve a website we will try to upgrade unsecured assets on-the-fly before rendering the website.
Over time we gathered additional rules by adding a Content-Security-Policy-Report-Only header and gathering the reported URLs. Later on we scraped these URLs and tried to upgrade them via some simple rules (e.g. by checking for valid redirects from HTTP to HTTPS). That way our “url-upgrader” actually “learned” over time and got better at doing its job.
In order to roll out HTTPS as soon as possible, the on-the-fly upgrader was a huge relief. Ultimately, though, we applied the generated rules once and for all to all our websites and let our url upgrader rest in peace.
Now one might think that HTTPS is HTTPS and that it always stays for a secure connection. But actually there are some quirks. One, for example, involving how you serve OCSP responses, if you have an HSTS header or not, and what cipher suites you support. Fortunately, Mozilla’s Observatory provides a way to scan a domain and rank its HTTPS setup (tips for how to improve included!).
In short, we went with caching OCSP responses server-side, using RSA instead of ECDSA (mainly because there are still a bunch of Windows XP users out there), and we set an HSTS header with a max-age of one week, as we are not yet brave enough to set HSTS headers for the recommended time frame of at least six months. As we didn’t want to monitor our websites manually, and to keep track of our rating, we developed and open sourced a little Prometheus exporter, which you can check out here.
Ship it!
Nothing is stable straight from the beginning and we expected things to go south in some way, so we went with a typical one-some-many release and learned on the way.
One thing we did learn the hard way is that leaking open challenges is a bad thing to do, and you have to revoke them if something goes wrong. That might be due to a network error, a code bug, or Let’s Encrypt being unable to reach the challenge endpoint for whatever reason. We hit this limit more than once until we revoked all authorizations safely and our only way out back then was switching accounts back and forth. It’s a good idea to keep track of all authorization attempts in some persistent way, including the authorization URL, just in case. Let’s Encrypt has a bunch of other limits that should be reviewed carefully. Their staging environment is noteworthy as well, but don’t let yourself be fooled by different limits in production.
Another issue we ran into was when trying to “guess” the result of an authorization at Let’s Encrypt. Whenever our API accepts a request, we expect it to complete successfully, otherwise it would show up in our dead letter queues. Well, guess what? Our dead letter queue was never empty. Our users are able to connect their own domain to their Jimdo website, therefore their DNS setup is not always under our control, and might just be misconfigured (e.g. is not targeting our servers). In this case we can’t issue a certificate for the given domain until they fix their DNS settings. In order to reject these requests to our certificate API as early as possible we added a simple DNS check. Initially we just used Google DNS, but later on extend our DNS check to include Level 3 DNS as well. This gave us the best method to guess the results from the Let’s Encrypt DNS. Google’s DNS is really strict compared to other providers, and some customers didn’t really care about getting picked up by Google’s DNS (Greetings, Japan!).
One other reason for Let’s Encrypt to not issue a certificate is if the domain is known to be malicious. They use the Google Safe Browsing API for detecting malicious websites, so we did too in our API to catch bad sites early on and reject the request.
Another tool that proved to be worthwhile is our regular game days where we try to break our systems, but that's an entirely different story – stay tuned!
The End
We rolled out HTTPS for custom domains in mid December 2016 and are now in a state where we are confident to disable HTTP access entirely.
We’d like to thank Let’s Encrypt for their great contribution to a more secure web (and the sweaters), making our undertaking tremendously easier - pay them a visit!
In case this got you excited and you’d like to help make website creation for millions of people as easy as pie - we are hiring!
Write a comment
work from home (Sunday, 17 September 2017 17:09)
It is imperative that we read blog post very carefully. I am already done it and find that this post is really amazing.
home based business (Sunday, 17 September 2017 17:10)
Wonderful illustrated information. I thank you about that. No doubt it will be very useful for my future projects. Would like to see some other posts on the same subject!
Muslim Black Magic Love Solution Expert (Friday, 27 October 2017 08:56)
Nice post i really like it
http://en.forrender.com/ (Friday, 17 November 2017 13:28)
Most of the time I don’t make comments on websites, but I'd like to say that this article really forced me to do so. Really nice post!
app developers brisbane (Wednesday, 29 November 2017 06:56)
Click here for get more information about it - http://www.appers.com.au/apps/
jose (Monday, 25 December 2017 03:10)
please apply option to disable this ssl if I want or not in the control panel no all widgets, iframes
they are compatible, it is truly annoying
Visit Website (Monday, 26 February 2018 06:49)
https://www.afdpro.com/
American Flyer Distribution. The Leading Source For Flyer Distribution, Flyer Design, Pamphlet Distribution, & Development"
Android Developers (Tuesday, 30 July 2019 21:21)
Really like the post.
admin (Saturday, 23 April 2022 17:22)
1
admin (Saturday, 23 April 2022 17:22)
1
asd'" (Wednesday, 04 May 2022 13:55)
asd'"><a
asd (Wednesday, 04 May 2022 13:56)
asd
asd (Wednesday, 04 May 2022 13:59)
asd
bb'" (Wednesday, 04 May 2022 13:59)
bb
increase da 50+ (Tuesday, 17 October 2023 23:56)
Extremely helpful post. This is my first time i visit here. I discovered such a large number of intriguing stuff in your blog particularly its exchange. Truly its extraordinary article. Keep it up.
increase da 50+ (Tuesday, 17 October 2023 23:57)
Extremely helpful post. This is my first time i visit here. I discovered such a large number of intriguing stuff in your blog particularly its exchange. Truly its extraordinary article. Keep it up.
increase da 50+ (Tuesday, 17 October 2023 23:58)
Extremely helpful post. This is my first time i visit here. I discovered such a large number of intriguing stuff in your blog particularly its exchange. Truly its extraordinary article. Keep it up. <a href="https://www.fiverr.com/ahsan_seo47/increase-your-website-domain-authority-50-plus-safe-and-guaranteed">increase da 50+</a>
tekla steel detailing jeemon vg (Friday, 20 October 2023 23:56)
I think this is an informative post and it is very useful and knowledgeable. therefore, I would like to thank you for the efforts you have made in writing this article.
tekla steel detailing jeemon vg (Saturday, 21 October 2023 21:29)
I think this is an informative post and it is very useful and knowledgeable. therefore, I would like to thank you for the efforts you have made in writing this article.
showbizztoday.com (Tuesday, 24 October 2023 23:54)
I really loved reading your blog. It was very well authored and easy to undertand. Unlike additional blogs I have read which are really not tht good. I also found your posts very interesting. In fact after reading. I had to go show it to my friend and he ejoyed it as well!
https://trendvariant.com/entertainment-lifestyle-music-fashion/ (Tuesday, 24 October 2023 23:55)
I really loved reading your blog. It was very well authored and easy to undertand. Unlike additional blogs I have read which are really not tht good. I also found your posts very interesting. In fact after reading. I had to go show it to my friend and he ejoyed it as well!