
At some point as a software developer you have to answer the following question:
"How can I migrate big systems or make big software changes while still reducing risk of breakage, outages or data loss?"
The first great method is Branch by Abstraction. It’s primarily for avoiding feature branches and stale code by branching within your mainline codebase and not with you version control system: It’s the real mindset of continuous integration, instead of a big rewrite in a feature branch you introduce a new layer into your software.
What we did at Jimdo for example is migrating all of our user uploaded files from a local storage into the cloud. Before even starting the migration we introduced a new storage layer within the code. The former way was kind of copy and paste programming like synthesizing the path to a file over and over again around the codebase without any unified interface. The new layer provided an indirection to the existing local storage, but without exposing the actual implementation (paths etc). We could implement the new layer step by step into the production codebase. Fun fact: Client code suddenly gets testable because you are able to stub your legacy storage layer implementation.
A problem we faced at this stage: How to ensure you won't break any existing code which has no unit or high level tests? We will get to this later.
So after having created a sane layer to our storage subsystem, we can start to implement the new shiny cloud storage layer implementation, of course with TDD :-). Next up have the challenge of migrating from the old to the new layer and everything without downtime!
But, this is really no big deal in the most cases. It’s data migration and has been done before. This is how we solved it for Jimdo:
First: Build a Migration Provider:
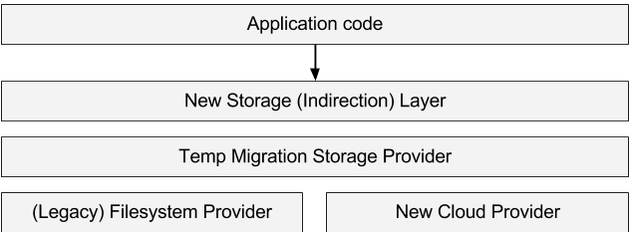
The migration storage provider is a decorator for the old and the new storage provider. So in the case of a “GET” it first asks the the filesystem provider for a file. If the filesystem provider HITs, the decorator will transparently remove it from the filesystem provider and push it to the cloud provider on-demand, and then of course return the requested file handle. In case of a miss in the filesystem it will ask the cloud provider for the file.
This is a really big advantage because migration is done one the fly. You may observe it for some time and once you are absolutely sure nothing broke, you just write a data migration “runner” script which has to “touch” all storage items once. NoSQL/Schemaless people will recognize with as their way to do “schema migrations”.
So once we migrated everything to the cloud provider, we are able to remove the migration decorator and the filesystem provider. Mission accomplished! Happy devs (burned old code), happy admins (less administration of file servers, less TCO), happy cloud provider (earns money), happy users (almost no migration impact, less bugs because of clean code). And: Happy business (feature development gets faster, scaling storage layer).
And what is really really important: This is AGILE. With this strategy we embrace change and changing priorities. We do not cause any waste. We can stop the migration at almost any point because the migration storage provider decorator hides away the complexity (even without actually doing the migration this is a big win!).
So how can we reduce the migration risk even more?
First: Feature Flips. It’s really cool if you have a configuration variable / flag around with lets you control the used storage layer. You can even roll back fast in case of a disaster. Some more tips below.
In conjunction with feature flips and a sharded architecture you could also enable the migration (fileserver-)shard-by-shard. A really cool method stolen from operations is “one, some, many” in order to start a progressive rollout: You first start with one shard, look if everything is ok, fix some stuff, then enable some more, fix some stuff - in the end just enable all shards when no problems have been reported for some time.
Now lets look into some more learnings we experienced during big migrations.
How to make sure you won’t break anything?
The answer is: You can do this up to a certain amount of effort. You have to weigh if you are touching the heart of your application or just a not so often used feature with less user impact.
The first rule of a migration is (it’s even sometimes a core company culture pattern):
“If you break it, will you even notice?”
It’s really important that you have the right monitoring in place in the case something breaks. Logging tools and metrics are extremely important tools to see if you broke something.
For example in our example we could measure how many jpeg images are uploaded. If the amount changed after we deployed some changes to our storage layer implementation, we should receive notifications that we broke something. Application logging also helps as we can see warnings, exceptions and so on, but there’s plenty of stuff written on those topics.
In our web application world we don’t build airplanes. We usually have the luxury to break things if we can fix it fast enough. People will just hit the reload button.
In our fast moving and highly competitive web world Meantime to repair (MTTR) gets more important than Meantime between failure (MTBF). Given a culture which embraces failures (and learning from it) as well as the technical foundation like fast restores in case of data loss or fast reprovisioning of services we are able to innovate and move forward faster.
This is how we come to the second rule:
“If you noticed it, can you even fix it?”
Now that we have the tools in place to monitor and measure our app, we “just” have to fix it.
Rollback should be possible at anytime: It’s really important that in case of critical bugs you have the possibility to roll back.
Example: If you change the behavior of the new storage layer of how files are moved around and there is a bug in the new path-synthesization-code (e. g. a missing file extension separator), files might get orphaned and just disappear because they are moved somewhere. Or you run into unknown concurrency bugs.
It’s really important to be as non-invasive as possible in such a case. For example instead of moving files around in our case we could just copy them, check if that works, and then change the code from “copy” to “move” (and cleanup the orphaned files which have been duplicated during the soft-migration phase).
How to break up untestable code?
This might explode the length of this article, but here are some tips if you don’t know how to write unit tests in order to ensure your new branch-by-abstraction indirection layer does not break anything. Even wrapping the old code into the new layer can introduce bugs. So here are some more tips:
-
Write high level acceptance tests, maybe with cucumber / Specification by Example. I noticed that code missing unit tests is often written for a feature which does not have a specification. So you might be in the awkward position of having to try to reverse engineer the spec first and write scenarios. Maybe even by doing a gemba walk through the office.
But those high level tests often have a higher business value than trying to unit-test nearly untestable code (for example you might be able reuse high-level cucumber specs. And it’s even writable/readable for non-dev people). -
Just hope that nothing breaks :-) But if it does, at least write some regression tests so a problem may not re-occur.
-
Read “the book” on how to deal with legacy code.
I hope this article gave you some insights how to reduce risk and minimize development waste by following some simple patterns.

Sönke has been going with Jimdo since it's beginning. He passionate about good trolling, distributed systems, knowledge management, devops, culture and scaling products as well as companies (and how those things may well play together)